
In deep learning, PyTorch is a powerful tool widely used by researchers and developers alike.
Due to GPU incompatibility, `torch.cuda.LongTensor` cannot be pinned to memory in PyTorch. CUDA devices cannot directly use this capability because it can only be pinned to dense CPU tensors.
In this article, we will explore the ins and outs of PyTorch’s memory pinning, answer common errors, and offer practical solutions to optimize your workflow for maximum efficiency.
What are dense CPU Tensor?
Dense CPU tensors are multi-dimensional arrays stored in your computer’s memory (RAM). Every element in a dense tensor is filled with a value, making it fully populated and ideal for machine learning and data processing tasks.
What is Pinned Memory?
Pinned memory refers to a type of memory in the computer that is locked, meaning the operating system can’t move it. In PyTorch, pinning memory helps transfer data quickly between the CPU and GPU.
This speeds up the process of training machine learning models, as data is readily available without delays, improving overall performance.
Understanding ‘torch.cuda.longtensor’ and Dense CPU Tensors
Scenario 1: Pinning ‘torch.cuda.longtensor’ to CPU Memory
Pinning a torch.cuda.LongTensor to CPU memory isn’t possible because it’s meant for GPU usage. Only dense CPU tensors can be pinned for efficient memory access and faster data transfer.
Scenario 2: Converting ‘torch.cuda.longtensor’ to Dense CPU Tensor
To fix the pinning issue, you can convert a torch.cuda.LongTensor to a dense CPU tensor. This makes the tensor compatible with memory pinning, improving data transfer speed for training models.
Scenario 3: Utilizing GPU Memory Efficiently
Efficient GPU memory use requires proper management of tensor types. Using torch.cuda.LongTensor properly minimizes unnecessary data transfers between CPU and GPU, which helps maximize GPU resources and avoid memory bottlenecks.
Scenario 4: Updating PyTorch Versions
Updating PyTorch ensures better compatibility with different tensor types, like torch.cuda.LongTensor. Newer versions may improve GPU-CPU memory handling, reducing errors related to tensor pinning and optimizing overall performance.
What is ‘torch.cuda.longtensor’?
1. Definition and Purpose
The purpose of torch.cuda.LongTensor is to handle large integer data on the GPU. It’s used for operations that require high-speed computation, helping optimize machine learning models with large datasets.
2. Differences Between Dense CPU Tensors and GPU Tensors
Dense CPU tensors are stored in RAM for faster access by the CPU, while GPU tensors are stored on the GPU memory, allowing for faster parallel processing of large data and computations.
Also Read: Docker Incompatible CPU Detected – Quick Fixes For Beginners
Pinning in PyTorch
1. Understanding Tensor Pinning
Tensor pinning in PyTorch ensures that certain data is locked in memory, preventing the OS from moving. This improves data transfer speed, crucial for fast GPU-CPU communication during model training.
2. Why ‘torch.cuda.longtensor’ Cannot Be Pinned
Torch.cuda.LongTensor cannot be pinned because it’s designed to work on the GPU. Pinning is only possible for CPU-based tensors, limiting its use in data transfer optimizations.
Peculiarities of CPU and GPU Tensors
1. Exploring Dense CPU Tensors
Dense CPU tensors are memory-efficient and designed for tasks performed on the CPU. These tensors allow fast data manipulation and are ideal for smaller datasets or when GPU resources are unavailable.
2. Limitations of Pinning GPU Tensors
Pinning GPU tensors is not supported because they reside in the GPU’s memory. Only CPU-based tensors can be pinned, which limits their direct usage for efficient data transfer to and from the GPU.
3. Implications for Machine Learning Tasks
Pinning issues with torch.cuda.LongTensor affect machine learning tasks by slowing down data transfer between CPU and GPU. This can impact model training efficiency and may require the conversion of tensors for optimization.
Common Errors and Debugging
- Error: Cannot Pin ‘torch.cuda.longtensor’: This error occurs because only dense CPU tensors can be pinned, not GPU tensors like torch.cuda.longtensor. The solution is to convert it to a CPU tensor first.
- Error in DataLoader Pinning: Sometimes, DataLoader can try to pin GPU tensors, causing issues. To fix this, ensure that only CPU tensors are pinned in the DataLoader to avoid runtime errors.
Alternatives and Workarounds
1. Using CPU Tensors for Pinning
Pinning works only with CPU tensors. If you want faster data transfer, use dense CPU tensors instead of GPU tensors to take advantage of pinning.
2. Modifying the Code to Accommodate GPU Constraints
Adjust your code to ensure GPU tensors are not pinned directly. Convert them to CPU tensors when needed or avoid unnecessary pinning to avoid errors.
Read Out: Ftpm Will Not Enable In New CPU – Troubleshooting Guide!
Best Practices in Tensor Handling
1. Optimizing Tensor Operations for Performance
Optimize tensor operations by minimizing memory transfer between CPU and GPU. Batch operations together, use efficient data types and avoid unnecessary tensor conversions to speed up performance.
2. Ensuring Compatibility Across Different Hardware Configurations
Ensure your code works across different hardware by checking tensor types, PyTorch versions, and CUDA configurations. Test with various setups to avoid errors like pinning issues.
How to Troubleshoot and Fix the Issue
Check if the tensor is a CPU tensor before pinning to fix pinning errors. If needed, convert GPU tensors to CPU and ensure compatibility with the correct PyTorch version.
Real-world Applications
In machine learning, proper tensor handling speeds up model training and data transfer. Pinning CPU tensors helps optimize data loading, while GPU tensors are used for computation-heavy tasks in deep learning models.
Community Discussions and Solutions
Many developers share their solutions to tensor pinning issues on forums like Stack Overflow. Read through these discussions to find fixes or workarounds others have found for your problem.
When Speed Bumps Your Code?
1. Pinning Memory for Seamless Data Transfer
Pinning memory helps move data quickly between CPU and GPU. This speeds up training by reducing delays in transferring large datasets, especially in deep learning applications.
2. Supported Tensors: Not All Heroes Wear Capes
Not all tensors can be pinned. Only dense CPU tensors are supported for pinning. Be mindful of this limitation when handling large datasets or model parameters.
Why the Error Occurs?
1. Misplaced pin_memory Enthusiasm
Sometimes, pin_memory=True is set unnecessarily, leading to errors. Only use it when transferring data between CPU and GPU to avoid unnecessary complications or wasted resources.
2. Dataloader’s Overeager Pinning
DataLoader might pin memory too early, leading to errors. Review the settings and ensure you’re pinning memory only when needed to avoid performance issues or memory allocation errors.
How to Fix It?
1. Pinning CPU Tensors for a Streamlined Journey
Pinning CPU tensors improves the speed of data transfer to the GPU. This reduces bottlenecks during training and speeds up model training time by ensuring faster data access.
2. Taming the Dataloader’s Spinning Enthusiasm
Sometimes, DataLoader tries to pin tensors too early, which can cause errors. Ensure that pinning is only done when necessary to keep your data flow efficient and avoid unnecessary overhead.
3. Additional Tips
To improve performance, carefully monitor memory usage and only pin necessary tensors. Avoid pinning GPU tensors or large data batches that do not require pinning, keeping your code optimized.
You Should Know: What Is Vddcr CPU Voltage? – Step-By-Step Guide In 2025!
Future Developments
1. Updates on PyTorch and CUDA Compatibility
Keep your PyTorch and CUDA versions up to date for better tensor support and compatibility. Regular updates provide new features and bug fixes that improve efficiency of tensor pinning and data handling.
2. Potential Resolutions for the ‘torch.cuda.longtensor’ Issue
The issue can be resolved by converting torch.cuda.longtensor to a CPU tensor before pinning. This workaround allows smooth data transfer and prevents errors related to unsupported tensor types.
How Does pin_memory work In Dataloader?
In PyTorch, setting pin_memory=True in DataLoader allows tensors to be stored in pinned memory, which speeds up the data transfer to the GPU, improving training performance.
Using Trainer with LayoutXLM for classification
When using the LayoutXLM model for classification tasks, the Trainer class can be utilized to automate training and evaluation. It simplifies model setup and makes it easier to manage training pipelines.
Pin_memory报错解决:runtimeerror: Cannot Pin ‘cudacomplexfloattype‘ Only Dense Cpu Tensors Can Be Pinned
This error happens when trying to pin unsupported tensor types. Ensure you’re pinning only dense CPU tensors, and avoid using types like cudacomplexfloattype that can’t be pinned.
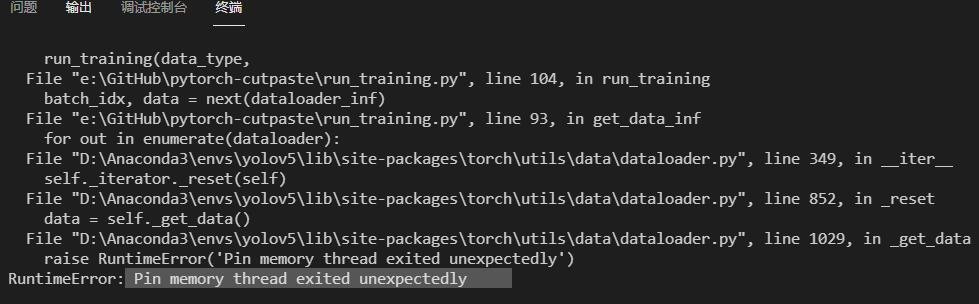
Runtimeerror: Pin Memory Thread Exited Unexpectedly
This error typically occurs when pinning memory fails, possibly due to incompatible tensor types. Ensure only supported tensors are pinned and check your environment and PyTorch version for compatibility.
Pytorch Not Using All GPU Memory
PyTorch may not fully utilize GPU memory if the batch size is too small or memory isn’t pre-allocated. Try increasing the batch size or adjusting memory management settings to optimize GPU usage.
Huggingface Trainer Use Only One Gpu
If Huggingface Trainer uses only one GPU, set device_map=”auto” or manually adjust the settings in your training script to enable multi-GPU usage for parallel processing.
Error during a fit of model #2
This error can occur due to mismatched input shapes or incompatible tensor types. Check the data processing pipeline, ensure the correct tensor types, and match input dimensions with your model’s expectations.
Doesn’t work with multi-process DataLoader #4
When using a multi-process DataLoader, ensure the num_workers parameter is set correctly. Adjust settings to prevent memory or process-related issues that cause the DataLoader to fail.
RuntimeError: cannot pin ‘torch.cuda.DoubleTensor’ on GPU on version 0.10.0 #164
This error arises when attempting to pin a torch.cuda.DoubleTensor, which is not supported for pinning. Convert tensors to a compatible type (e.g., FloatTensor) for successful pinning and data transfer.
Should I turn off `pin_memory` when I already loaded the image to the GPU in `__getitem__`?
Yes, if you’ve already loaded the image to the GPU in __getitem__, turning off pin_memory can avoid redundant memory pinning and improve performance. Pinning should only be done when necessary.
GPU utilization 0 PyTorch
When GPU utilization is zero in PyTorch, it could mean the model isn’t properly utilizing the GPU. Check your batch size and data pipeline, and ensure your model is correctly transferred to the GPU.
When to set pin_memory to true?
Set pin_memory=True in DataLoader when working with large datasets and transferring them to the GPU. It improves data loading speed by ensuring faster memory access during training or inference.
Need To Know: Can I Use 70 Alcohol To Clean CPU – A Detailed Guide 2025!
Pytorch pin_memory out of memory
If you get an “out of memory” error with pin_memory=True, try reducing the batch size or using more memory-efficient operations. Too many pinned tensors can overload GPU memory.
Can’t send PyTorch tensor to Cuda
This error usually happens when trying to move a tensor to the GPU, but it’s already on a different device or is an incompatible type. Ensure the tensor is created and transferred correctly.
Differences between `torch.Tensor` and `torch.cuda.Tensor`
Torch.Tensor is used for CPU operations, while torch.cuda.Tensor is specifically for GPU operations. The latter is stored in GPU memory, allowing faster CUDA acceleration computations.
Torch.Tensor — PyTorch 2.3 documentation
The torch.Tensor class in PyTorch represents a multi-dimensional matrix. It can be used for CPU and GPU operations, with CPU tensors defaulting to CPU memory and CUDA tensors using GPU memory.
Optimize PyTorch Performance for Speed and Memory Efficiency (2022)
In 2022, optimizing PyTorch for performance includes:
- Using mixed precision.
- Efficient data pipelines.
- Reducing memory overhead.
- Use batch sizes that fit your GPU’s memory for maximum efficiency.
RuntimeError Caught RuntimeError in pin memory thread for device 0
This error often occurs if there’s a problem pinning memory, possibly due to incorrect tensor types. Ensure the tensor is CPU-based and compatible with pinning. Double-check your data loader settings.
How does DataLoader pin_memory=True help with data loading speed?
Setting pin_memory=True in DataLoader allows data to be transferred to the GPU faster using page-locked memory. This reduces the waiting time for the GPU to process data during training.
PyTorch expected CPU got CUDA tensor
This error occurs when PyTorch expects a CPU tensor but receives a CUDA tensor instead. Convert your tensor to the correct device (CPU or CUDA) before performing operations.
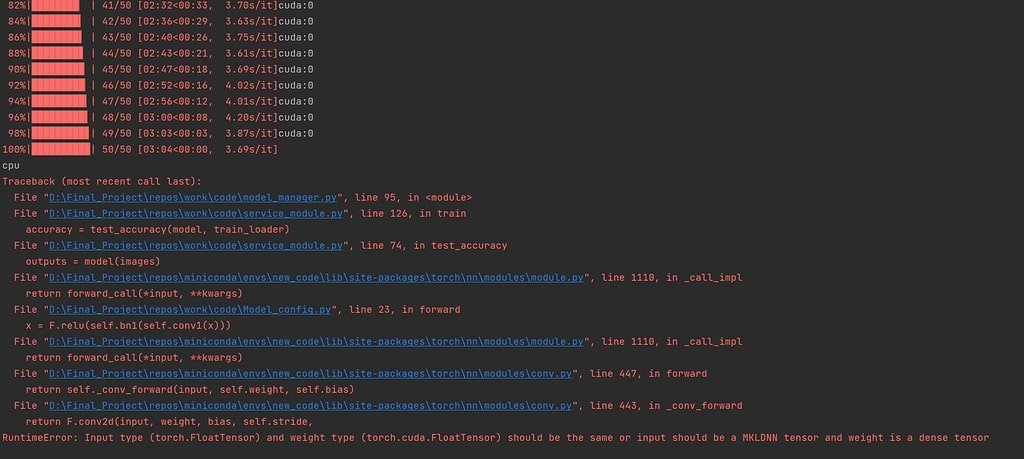
RuntimeError: Input type (torch.FloatTensor) and weight type (torch.cuda.FloatTensor) should be the same
This error happens when the model’s input and weights are on different devices (CPU vs. GPU). Ensure the input and weights are moved to the same device for compatibility.
RuntimeError: _share_filename_: only available on CPU
This error happens because certain functions like _share_filename_ only work on CPU tensors. If you use GPU tensors, switch them to CPU for specific operations like shared file handling.
Tensor pin_memory
pin_memory in PyTorch locks memory pages for faster transfer to the GPU. This helps improve data loading speed when working with large datasets or training models.
DataLoader pin memory
Setting pin_memory=True in DataLoader speeds up the data transfer from CPU to GPU. It locks the data in memory so the GPU can access it more quickly during training.
Pin_memory=false
Setting pin_memory=False disables memory pinning in DataLoader. It can save CPU memory and may be helpful when running into memory issues, but it could slow down data transfer speed.
When is pinning memory useful for tensors (beyond dataloaders)?
Pinning memory is useful for tensors when quickly transferring data between CPU and GPU. It minimizes the time it takes to send data during training or inference.
Runtimeerror: caught Runtimeerror in pin memory thread for device 0.
This error typically happens when there’s an issue pinning memory, possibly due to incorrect tensor types or memory allocation. Check if the tensor is on the right device and compatible with pinning.
Vllm Producer process has been terminated before all shared CUDA tensors released
This error means that CUDA tensors were not properly released before the process ended. Ensure you manage memory and release tensors before terminating processes to avoid memory leaks.
Using pin_memory=False as WSL is detected This may slow down the performance
When running PyTorch on Windows Subsystem for Linux (WSL), setting pin_memory=False can avoid memory issues but might slow down performance. Adjust this setting based on your system’s needs.
FAQs
1. What does pin_memory do in PyTorch?
pin_memory in PyTorch locks CPU memory for faster transfer to the GPU, improving data loading performance during training or inference.
2. What is torch CUDA using?
Torch.cuda in PyTorch allows the use of GPU for tensor computations. It provides methods to manage and manipulate CUDA-enabled GPUs.
3. What is the difference between PyTorch and TorchScript?
PyTorch is a dynamic framework for deep learning, while TorchScript is a way to serialize and optimize models for efficient deployment.
4. What does Torch Manual_seed do?
Torch.manual_seed sets the random seed for reproducibility in experiments, ensuring the same results each time the code is run.
5. What does num workers do in PyTorch?
num_workers in PyTorch defines how many CPU processes handle data loading. More workers can speed up data loading by parallelizing it.
6. How can I avoid encountering this error in the future?
Ensure you’re only pinning dense CPU tensors, not GPU tensors. Check and handle your tensor types correctly to prevent pinning issues in future model training or data transfer.
7. Can I pin other types of GPU tensors to CPU memory?
No, GPU tensors like torch.cuda.LongTensor can’t be pinned. Only dense CPU tensors can be pinned to improve memory access and data transfer speeds between CPU and GPU.
8. Are there any alternatives to pinning ‘torch.cuda.longtensor’?
To resolve this, you can convert torch.cuda.LongTensor to a dense CPU tensor using .cpu() method. This makes it compatible with pinning, improving data transfer during model training.
9. What does the error message “Cannot Pin ‘torch.cuda.longtensor’ Only Dense CPU Tensors Can Be Pinned” mean?
This error means that torch.cuda.LongTensor cannot be pinned to memory because it’s a GPU tensor. Only dense CPU tensors can be pinned to optimize memory transfer speed.
10. How can I resolve the “Cannot Pin ‘torch.cuda.longtensor’ Only Dense CPU Tensors Can Be Pinned” error?
To fix the error, convert torch.cuda.LongTensor to a dense CPU tensor using .cpu(). This will allow the tensor to be pinned, enabling better memory management and faster data transfer.
Conclusion
In conclusion, understanding tensor pinning in PyTorch and managing memory efficiently is crucial for optimizing deep learning workflows. You can improve data transfer and model performance by converting tensors, using proper pinning techniques, and staying updated with PyTorch.