
FP16 and FP32 are two floating-point formats commonly used in computing, each offering unique benefits. While FP16, or half-precision, is known for its speed and memory efficiency, FP32, or single-precision, offers higher accuracy and precision.
FP16 is not supported on CPUs due to the lack of native 16-bit floating-point arithmetic. CPUs use FP32 instead, which provides higher precision but can lead to slower performance for certain tasks.
In this article, we’ll explore why CPUs don’t support FP16, its impact, and how alternatives like GPUs and specialized techniques can help optimize performance.
Why FP16 is Not Supported on CPU
FP16, also called half-precision floating-point, is a smaller, faster format for handling numbers in tasks like deep learning. So why don’t CPUs support it? The main reason is that CPUs were built with different priorities. CPUs focus on being flexible and reliable for general tasks, like running software or handling data. They rely on formats like FP32 (single-precision floating-point), which are accurate and versatile enough for most situations.
Adding FP16 support to CPUs would mean rethinking their design and adding specialized hardware. This would make CPUs more expensive and complex, which doesn’t make sense for most users who don’t need FP16. Historically, tasks that benefit from FP16 (like AI and machine learning) weren’t a priority when CPUs were first designed. As a result, CPUs never developed the ability to process FP16 efficiently.
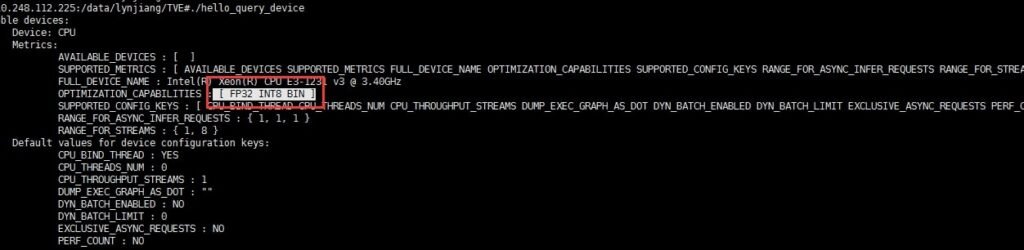
Another issue is demand. Most applications don’t need FP16’s reduced precision. Developers prefer FP32 because it provides better accuracy and works well for various uses. This makes it more practical to optimize CPUs for FP32 rather than invest in FP16 support.
Instead of CPUs, GPUs (graphics processing units) are better suited for FP16 tasks. GPUs have hardware built for this kind of computation, making them a perfect match for workloads that need FP16’s speed and efficiency. While CPUs may not natively support FP16, they can still simulate it using FP32, ensuring compatibility where needed.
1. Implications of Using FP32 Instead of FP16 on CPUs
Using FP32 instead of FP16 on CPUs has several effects on performance, memory usage, and overall efficiency. Here’s how it impacts your work:
- Increased Memory Consumption
- FP32 requires twice the memory compared to FP16 to store the same data.
- This can lead to higher memory usage, especially when working with large datasets.
- Reduced Processing Speed
- FP32 calculations demand more computational resources than FP16.
- Tasks that involve heavy floating-point operations may run slower on CPUs using FP32.
- Better Precision
- FP32 provides more accuracy compared to FP16, which is beneficial for applications where precision is critical.
- However, in tasks where FP16 would be sufficient, FP32’s extra precision might go unused.
- Increased Power Consumption
- The higher computational load of FP32 can result in more energy use, impacting power efficiency.
- Compatibility Advantages
- FP32 is widely supported across all CPUs, ensuring compatibility with most software and applications.
- This makes it a safer choice for developers working on diverse systems.
- Limitations for Specialized Tasks
- For tasks like deep learning or AI, FP16 offers significant advantages in speed and memory efficiency.
- Without native FP16 support, CPUs may not be ideal for such workloads.
While FP32 is reliable and versatile, understanding these implications helps you choose the right hardware and techniques for your specific needs.
Also Read: Cannot Pin ‘Torch.Cuda.Longtensor’ Only Dense CPU Tensors Can Be Pinned
Alternatives to FP16 on CPUs
1. GPGPUs (General-Purpose Graphics Processing Units)
GPUs are a powerful alternative for FP16 tasks. Unlike CPUs, GPUs are designed for parallel processing and include hardware dedicated to FP16 computations. This makes them ideal for workloads like deep learning, AI training, and simulations.
With GPUs, tasks that rely on FP16 precision run faster, use less memory, and consume less power than CPUs using FP32.
While integrating GPUs may require learning new software tools, their performance boost often justifies the effort.
For anyone working with FP16 or computationally heavy applications, GPUs provide an accessible and highly efficient solution that significantly outperforms CPUs in these scenarios.
2. Quantization and Model Compression
Quantization is a clever technique that works around FP16 limitations. It converts data or models to lower-precision formats like FP16 or INT8, reducing memory use and speeding up computations.
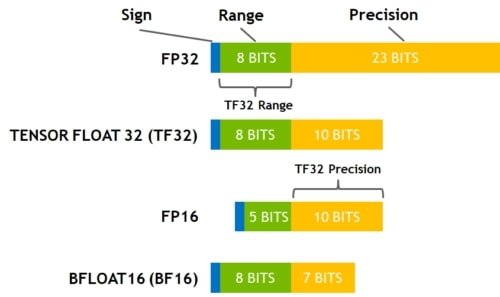
This is especially useful for deploying deep learning models on resource-limited devices like CPUs. Model compression further optimizes memory and computational efficiency by reducing model complexity without severely affecting accuracy.
While quantization may lead to slight accuracy trade-offs, the performance gains and reduced resource demands make it a valuable strategy.
These methods allow developers to achieve faster processing and more efficient memory usage, even when CPUs lack FP16 support.
3. Hardware Accelerators
Hardware accelerators like TPUs and AI processors are game-changers for tasks requiring FP16. These specialized devices are built for speed and precision, offering unmatched performance in areas like AI, machine learning, and large-scale simulations.
Unlike CPUs, they handle FP16 calculations natively, enabling faster and more efficient processing. While accelerators are more expensive than traditional hardware, their ability to handle intensive workloads with reduced power and memory usage makes them worth the investment.
For professionals tackling demanding computational tasks, hardware accelerators provide a reliable solution that combines efficiency, speed, and the full benefits of FP16 support.
Must Read: Pinnacle Raven Or Summit Ridge CPU: Which One Suits You!
FP16 is not supported on CPU; using FP32 instead mac
Mac CPUs don’t support FP16 because they focus on general-purpose tasks that benefit from FP32’s precision. FP16, though faster and more memory-efficient, isn’t natively compatible with CPUs.
Instead, Macs rely on FP32 for reliability and accuracy. A GPU is recommended for FP16-heavy tasks like deep learning as it provides dedicated support for FP16 operations.
This ensures optimal performance while allowing Macs to maintain their core strengths in precision and versatility.
Whisper FP16 vs fp32
Whisper performs faster with FP16 as it uses less memory and processes data quickly but requires compatible hardware like GPUs.
On CPUs, Whisper defaults to FP32, which offers higher precision but slower performance. If you aim for speed and efficiency, ensure your hardware supports FP16.
For general use, FP32 on CPUs ensures reliable transcription with accurate results, even if it sacrifices some speed compared to GPU-accelerated FP16.
DeepSpeed Type fp16 is not supported
DeepSpeed optimizes AI training with FP16 for speed and lower resource usage. However, if FP16 isn’t supported on your hardware, it switches to FP32, which is slower but universally compatible. This fallback guarantees training can still proceed without errors.
To fully leverage FP16’s efficiency, ensure your setup includes a compatible GPU. Adding GPU support will allow DeepSpeed to process faster and reduce the training time significantly.
Fp16 on CPU
CPUs don’t natively support FP16 because they prioritize compatibility and precision, which FP32 provides.
While FP16 saves memory faster, CPUs emulate it using FP32, leading to slower processing. GPUs are better suited for tasks requiring FP16, as they have specialized hardware for efficient FP16 computations.
CPUs can handle general workloads well, but GPUs unlock FP16’s true potential for AI or deep learning.
Whisper not using GPU
If Whisper isn’t using your GPU, it will default to your CPU, which supports only FP32. This can slow performance and increase memory usage.

To fix this, ensure your GPU is correctly configured and the necessary drivers are installed. Modify Whisper’s settings to force GPU usage for FP16 support.
A GPU will make Whisper run faster and more efficiently, providing smoother transcription performance for intensive tasks.
Need To Know: CPU Machine Check Architecture Error Dump – Best Guidance!
Stable Diffusion FP16 vs FP32
FP16 is ideal for Stable Diffusion on GPUs, offering faster processing and reduced memory usage. Only FP32 is supported on CPUs, ensuring accuracy but operating more slowly.
If you’re working on large-scale projects or require high efficiency, FP16 with a GPU is the best choice. However, for simpler tasks or non-GPU setups, FP32 still delivers reliable results while maintaining compatibility across systems.
FP16 vs FP32 vs FP64
- FP16: Fast and memory-efficient but less precise, suitable for AI and gaming.
- FP32: A balance of precision and speed, versatile for most applications.
- FP64: High precision, slow, and resource-intensive, ideal for scientific work.
- Choose based on task complexity: FP16 for speed, FP32 for versatility, and FP64 for extreme accuracy.
Whisper filenotfounderror: [winerror 2] the system cannot find the file specified
This error occurs when Whisper can’t find a required file. Check your file paths and ensure all dependencies, models, and necessary components are installed in the correct directories.
Confirm your Python environment is set up properly and that any updates haven’t altered file locations. Reinstalling Whisper or double-checking configurations often resolves the issue. Properly organizing your files will help avoid similar errors in the future.
FAQs
1. What is the significance of FP16 and FP32 in CPU?
FP16 and FP32 are numerical formats for calculations. FP16 uses less memory and speeds up tasks, while FP32 offers higher precision.
2. Why does the CPU not support FP16 operations?
CPUs prioritize general-purpose tasks and are optimized for FP32. FP16 requires specialized hardware, which CPUs typically don’t have.
3. In what scenarios is FP16 typically used?
FP16 is commonly used in deep learning, AI, and gaming, where speed and memory efficiency are crucial, especially on GPUs.
4. Are there any disadvantages to using FP32 instead of FP16 on the CPU?
FP32 can lead to higher memory consumption and slower performance, especially in tasks that benefit from FP16’s speed and efficiency.
5. Is there a way to overcome the lack of FP16 support on the CPU?
To overcome this, you can use GPUs, specialized hardware, or software techniques like quantization that simulate FP16 operations for better performance.
6. What is the difference between FP16 and FP32 in CPU?
FP16 uses 16 bits for calculations, offering faster performance and less memory usage, while FP32 uses 32 bits, providing more precision.
7. Which GPUs support FP16?
Most modern GPUs, including Nvidia’s Tesla, RTX, and A100 series, support FP16. These GPUs offer optimized performance for AI and machine learning.
8. What is FP16 used for?
FP16 is mainly used in machine learning, AI, and graphics processing, where speed and reduced memory usage are essential for large data sets.
9. Is FP32 single precision?
Yes, FP32 is known as single precision, using 32 bits to represent floating-point numbers. It balances speed and precision for general computing tasks.
10. Does P100 support FP16?
Yes, the Nvidia P100 GPU supports FP16, enabling faster AI and machine learning processing compared to FP32.
Conclusion
In summary, FP16 is not supported on CPUs due to their design prioritizing general-purpose tasks with FP32 for precision and versatility. While FP16 is faster and more memory-efficient, CPUs are not optimized. For tasks that benefit from FP16, using GPUs or specialized hardware accelerators is a better solution. These alternatives offer faster processing and better memory management. Understanding when to use FP32 or FP16 depends on your specific needs, ensuring you choose the right hardware and techniques for optimal performance.